User interfaces change with the times. A 3½" diskette as an icon in apps may now be obscure because hardly anyone has seen the physical object in 25 years, and applications based on swiping have functional differences from older mouse- or keyboard-based ones. That isn't what I have in mind today. Apps that swipe may be fashionable, but the swiping is at least partly a matter of function. This post is about pure visual fashion — choosing particular kinds of shapes, sizes, fonts, colours, textures and animations instead of other kinds.
I'll discuss a modern, stylish photo from a web site that's 100% about popular fashion, and then a screenshot of a modern, stylish android app. By popular fashion I mean fashion that comes from the vox populi rather than from designers in Paris or the Vogue editors. Instagram's click-fuelled feedback loop produces that, I think, and the photo below is arch-instagram. The app is a high-quality app from a small company. They couldn't be more different, and what I'll describe is their similarity. I think their difference permits a focus on generic visual fashion.

The lady is wearing a workman's overalls, turned into a swimsuit, or maybe a swimsuit made out to look like a workman's overalls. The colour, texture and pocket are those of a workman's overalls, the rest is clearly a swimsuit.
The photo is low in detail, with many nearly single-colour areas, with high contrast between the areas and some vivid details.
It is rich in action even though there's no movement. Even though most parts are nearly monochrone, the total photo uses colours and other elements to be maximally striking:
- The overalls-swimsuit constrasts with itself,
- the boobs and long blond hair attract the eye,
- the two meanings of painter busy the viewer's subconscious,
- the photoshop-enhanced edges make everything stand out,
- last but not least, her face is stands out by being rich in colour.
A advertising/logo designer I met talked about using intrinsic contrasts and asymmetries to attract and keep people's attention. He would love how the overalls she wears are the kind used by a painter to paint a house, while the palette she holds is the kind used by a painter to paint a painting. So is she a painter or a painter? Just the thing to make the subconscious direct your attention at the photo and keep it there for a few seconds extra.
Now that you've had your attention on it for so long, here's a link to buy it, directly from the designer.
Next, the app.
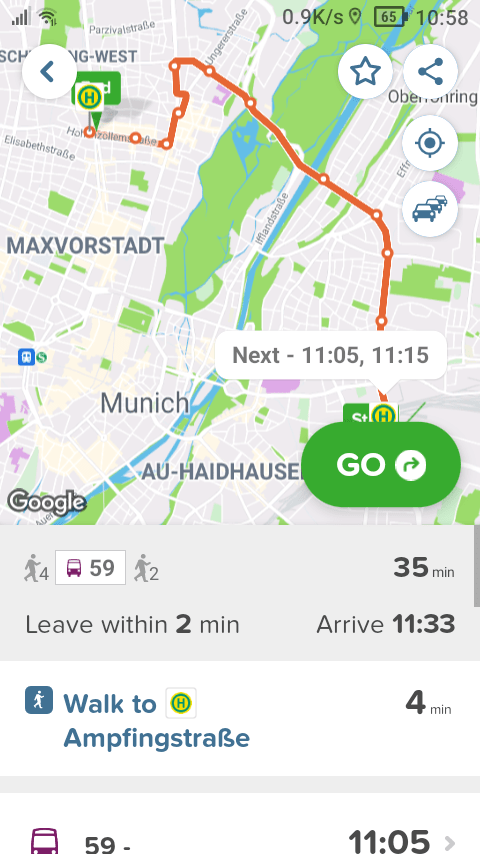
This uses subdued colour palette in most areas. Note the dampened details and a restricted palette in the map, which is subdued enough to work as a background, even while it has enough contrast to be usable on a smartphone screen in sunlight.
The app uses a single font, and the general visual language matches the font. The rounded corners look like the rounded letters.
The app avoids ornaments. There are no active screen edges, and the number of frames and borders is kept to a minimum. There are only three things: A map, a form and a button.
However, there's very strong contrast between those three. The GO button got all the emphasis: a vivid colour, upper case, bold text and it's even animated. The others are subdued, the map with few colours and the form with few details.
Just like the photo, the app uses the entire colour spectrum and every available kind of emphasis, but only once. Most things are subdued, restrained, and then one thing stands out!
The bold text: Little, but very bold. Larger text: Little, but very large (and in upper case). The colours: One colour is strong, and it's used sparingly, the rest of the colour use is restrained. The app uses animation, once.
Every kind of emphasis is used, but only once each. These pictures aren't unusually calm by historical standards, and not unusually noisy either, but both of them use contrasts deliberately.
Both of them restrain themselves in general, so that they can use even more contrast in the exceptions. That, I think, is the core of early-twenties visual fashion.
The app is called Citymapper and here's a link to the app itself. It's a great app, both functionally and in the way it uses early-twenties fashion.
As a footnote, I'm not suggesting to use this design. It looks modern, but looking modern isn't necessarily appropriate and this way isn't the only way to look modern, either. I am suggesting that apps use design, and that it's better for the apps and users if that design is thoughtful. Using the system font can be a thoughtful design choice, or just thoughtless.
Thoughtfully choosing to use the system font etc is fine. Noone gets fired for buying IBM and choosing to look conventional is a fine choice.
Here is a portrait of a Vogue editor, with a hairstyle rather like my own and looking both conventional and modern in a different way, or is it really so different? Her use of jewelry is subdued, but the ring is a big one. Her colour scheme is restrained, but with one strongly contrasting element, namely the dots. She uses elements of modern visual fashion to achieve a rather different look, a sort of timeless modernity. She looks as if she knows what she's doing. What decisions did she make to she achieve that look?
The same decisions could produce a fine user interface for an app.
I too started with that. A magnificent machine. Simple, with no chips to poke around and configure, so the only way to do anything was to write clever code.
I didn't realise how important the manual was until The Register quoted Steve Vickers, the author of the manual:
When I was writing the manual, the one thing I really wanted to avoid was the kind of brick wall that you can get to when you're just following along and then suddenly hit a wall where, unless you take on board a huge amount of understanding, you just can't make any progress.
[…More…]
A mere ten years after I promised to write this: here's a post describing how to write decent class documentation, for programmers, not writers. This describes how I wrote class documentation for Qt.
This has four parts: Write a sentence-long blurb with the most important thing you can say about the class. Write a few more sentences to give a complete, but rough overview of what the class is (is, not does). Make a list of methods, member variables, enum values and other subordinates of the class, sort the list into aspects, then write about each aspect (but not each member). Finally, make zero or more examples. […More…]
My favourite Stack Overflow answer is for a deleted question. The question was off-topic by the site's rules, which steer away from opinions and possible controversy and towards the purely factual, so deleting it was right. But.
The question (this one, visible only if you have ten thousand internet points) was what real life good habits has programming given you?
and the answer I so appreciate was by Robert Rossney, who wrote:
I no longer equate thinking I'm right about something with actually being right about it.
It's now very easy for me to entertain the thought that I may be wrong even when I feel pretty strongly that I'm right. Even if I've been quite forceful about something I believe, I'm able to back down very quickly in the face of contradicting evidence. I have no embarrassment about admitting that I was wrong about something.
That all came from decades of working in a discipline that mercilessly proves you to be mistaken a dozen times a day, but that also requires you to believe you're right if you're going to make any progress at all.
I was doing my insufficient best to implement java's turing-complete type system on the day I first saw this, and it hurt. Artist unknown. I'd love to see other works.

I'm angry now.
Last Friday I spent ten minutes writing bugfree valuable code. I also needed to write some entirely straightforward code to interface the new code to the rest of the world, build it in a test environment, and change the test environment a little to accommodate the new test.
Ten minutes of brainwork, perhaps an hour of drudges, the rest of the day to fix bugs related to the drudgery, and once the drudgery worked I saw that my ten minutes' brainwork worked perfectly.
It's not usually that extreme, but this isn't unique and I want it to stop. I want the bugs to relate more to brainwork, less to time spent typing.
Most of the day was wasted on a qemu/kvm surprise. I used a qemu/kvm virtual instance for testing, and either qemu or kvm (can't keep them apart, sorry) behaves oddly if the host system has several ethernet and VPN interfaces. The code unter test could talk to one part of the world, but not to another part, and as a result I spent a day staring at puzzling test failures.
Do I get to blame qemu/kvm? Perhaps, perhaps not. In one way, what bit me was a classic leaky abstraction. The virtual instance's routing table was plain and simple, but the host system's routing leaked through and so packets to some destinations were lost.
Blaming KVM may be fun pedantry, but doesn't get to the heart of the problem: Why chores are bug-affine. So here's hypothesis 2: Some chores are bug-affine and I can't tell in advance whether a particular chore is. The only solution in that case is to avoid chores. That's software sucks, so use less of it
again, so here comes hypothesis 3: Some activities are bug-affine and others less so, and the whether a particular change is interesting or just a chore doesn't matter for bug affinity.
Today I have implemented two features (or fixed two bugs, depending on viewpoint). This morning I thought they were roughly equally difficult. This afternoon I know that one took eight hours and more than 200 lines of code, the other took fifteen minutes.
I don't even seem to get better at estimation as the years go by. This is frustrating.
Software is changing. So are its problems.
Software today is developed in a more regimented and orderly manner than twenty years ago. A few good practices have taken hold:
- Version control
- Code review
- A sort of of agile development
- Coding standards
- Wide use of libraries, toolkits and frameworks
These are good things. Even if the agile development is often a parody of what it could be, it's still a net positive factor, in my opinion.
These good things have bad effects, too. Perhaps most notably, developers don't know what their third-party code does, and that affects what they know about their own software, and what the users can know and do.
Code gets used because of some known function, without anyone learning the full scope of functionality. Take Ruby on Rails and the action-mailer package, for example. If you want to send HTML, you probably want an add-on package that modifies your site's CSS for common mail reader compatibility, Premailer is the most common one.
There will be an issue in the issue tracker to add Premailer and fix CSS compatibiliy. Some team member will take the issue, add the necessary five lines of code, test that it looks right in gmail and outlook, write a test, and that was it. The premailer web site doesn't say whether premailer takes care of printouts (@media print {...} in CSS), and most likely noone on the team will ever know whether that works or not.
That lack of knowledge results in poor documentation and bugs around the edges. The team doesn't know everything its software actually does, […More…]
The supervisor kills the master and then the slaves elect a new master.
There. A plausible and reasonable sentence from the documentation of many distributed computer system systems, don't you agree?
But perhaps shocking to people who aren't familiar with the jargon. Is that a problem? Is the language too colourful? Or if it isn't a problem, is it in poor taste?
I've been pondering this yet again since the recent libreboot fiasco. I expect the real story of that is that Richard Stallman behaved like a prick for the hundredth time and offended Leah Rowe. A side story is that now, Leah Rowe says Stallman calls women who haven't used emacs emacs virgins
. It's true, he does, but it's still wrong: He calls anyone who hasn't used emacs that, man or woman.
I suppose emacs virgin
sounds different when Stallman leers at you while saying it.
It's not something one does often, but I've implemented the same feature in three different programs. Not very different, all are written in the same programming language for the same platform, and all are servers.
Same platform, same language, same task, same developer... you would think the three patches would end up looking similar? They did not, not at all.
The feature I wrote is is support for using UTF8 on SMTP, which I've implemented for Postfix, Sendmail and Qmail, which all run on linux/posix systems. I tried to follow the code style for each of them, and surprised myself at how different my code looked.
One patch is well-engineered, prim and proper.
The next is for an amorphous blob of software. The patch is itself amorphous, and makes functions even longer that were too long already. Yet it's half as long as the first patch. The two are, in my own judgment, about equally readable. One wins on length, the other on readability, they're roughly tied overall. This surprised me not a little.
The third is a short, readable patch which one might call an inspired hack. It's a much smaller than the others and easily wins on readability too.
It wasn't supposed to be like that, was it? Good engineering shouldn't give the most verbose patch, and the hack shouldn't be the most lucid of the three.
I see two things here:
First: Proper engineering has its value, but perhaps not as much as common wisdom says. Moderately clean code offers almost all of the value of really clean code.
Second: A small program is easy to work with, such as the MVPs that are so fashionable these days. But ease of modification isn't all, the smallest among the three servers has fallen out of use because the world changed and it stopped being viable.
Some random verbiage on each of the three servers and patches: […More…]
I like code review but complain about it all the time. Why? The other day I had an eureka moment: There are two quite different kinds, which I will give the misleading names agile review and waterfall review, and I'm annoyed when the reviewers perform one kind of review and I want the other.
Waterfall development is centered around planning, development and deployment in stages: First plan well and get rid of most bugs, then implement what's planned, then review and test to fix the remaining bugs, then deploy. In this model, code review focuses on catching minor bugs, ensuring code style harmony, proper use of internal/thirdparty APIs, etc. Big questions such as is this feature a good idea at all?
are out of scope, because that's been settled in the planning phase. (I'm not saying waterfall works in practice, only describing the theory.)
Agile development is different. Instead of planning well, agile development is based around an iterative process: Implement something that seems to be a good idea, consider it, learn something from it, finish it and then deploy, then pick something else to do, something one now knows more about. Code review can be the first part of the consideration and learning process, so it's a good time to discover that although a feature seemed like a good idea, it's going to be a morass and should be dropped at once. […More…]
The first thing I learned about programming in-person (not from a book or from code) was morbid bindings, a strangely unused term.
I learned it from a university employee called Eric Monteiro, who was oddly clueful in a generally sparsely beclued environment. Can't remember his title, or what he taught.
I had just listened to Eric answer someone else about multiple inheritance, and asked a followup question, which he answered, and then he digressed into relationships in general: When two things are connected in a program, the binding is always one of three: A kind, a belonging, or else it's morbid, and morbid bindings always turn out to be bad in one way or another.
He gave me a quick example: This number in this file has to be at the same as that number in that file
and I think I answered, such as maximum line length in two functions that read/write the same file?
[…More…]
A programmer doesn't always know whether a new feature of a program will turn out to be valuable or not. Perhaps: doesn't even often know. I've just had a repeat lesson on that topic.
I have a new phone. The manufacturer brags about a high-resolution camera and many other things, but I bought it because it's the smallest phone with a good screen and an up-to-date version of Android. (Yes it fits in a pocket, even sideways in some pockets.) I noticed in a review on the web that the phone's watertight, complete with an underwater photo of a beauty in bikini, but didn't give any thought to it. After all I don't spend much time in pools or at beaches, and if I do the bikini beauties don't gravitate towards me. When I bought the phone I had no idea that I would care about its being waterproof.
But I do care. The summer rains here in Munich can be impressively intense. Until now I've always been conscious that I was exposing an expensive and fragile electronic device to water when I used a phone in the rain. I have done that when I needed to, but in a corner of my mind I was always aware of the risk. Now I just do whatever I need to do, rain or shine, and don't worry about the device.
It's not particularly sensible, and not related to any software architecture I deal with at the moment, but I do want to post this photograph. Nominally it's is a photo of the concrete kind of architecture, not the software kind, but doesn't it look like an enterprise-ready, flexible, feature-rich and polished staircase framework?

It's from a hotel interior, so I expect there's a lift off-camera that people use when they want to get anywhere.
Here is a simplified version of function I once wrote:
if(foo() && bar())
return true; // common case
else if(foo())
return false; // happens too...
else if(mumble() == jumble() && bar())
return true;
else if(mumble() == jumble() && rotten())
throw new MalevolentClientException( ... );
else if(mumble() == null)
return true;
return false;
The real foo() was something along the lines of getRequest().getClientIpAddress().isRoutable(), so not awfully cheap, but it was O(1).
As you've noticed, foo() may be called twice even though the second return value has to be the same as the first. The function could be more efficient:
if(foo()) {
if(bar())
return true;
return false;
} else if(… […More…]
I am the fool who tweaked Qt to work with long-distance X11. The main problem was slow startup; if the ping time to the display was 0.1s, then applications needed 0.5s or more to start. So I fixed that, tested it using Qt/X11 applications on a transatlantic link, then fixed whatever else that I noticed because of the slow link.
As far as I know, noone ever made use of this work.
That didn't prevent someone at Trolltech from trying some of the same again twelve years later, except this time with better buzzwords and more effort.
So why did I do it? I don't remember. Perhaps someone had told me that X11 was network-agnostic by design and Qt's implementation fell short of the design, and I let myself be persuaded. Perhaps I told myself. One thing is sure: Noone had told me that this was a problem for their actual, concrete, existing application.
Maybe my work helped sell a seat or two for Qt. Many people are willing to pay for features or performance they don't need, so it's entirely possible. But I think it was probably waste. I feel good about it, though, because quite recently I was able to avoid a mistake by having learned from those two.
I've been a professional programmer for twenty years now. That seems to be long enough that for whatever mistake anyone proposes to make, I have made or watched a similar mistake at least once before. I'm not sure whether that's good or bad. Seeing a mistake be repeated is such a sad feeling.
Once upon a time, twenty years ago now, Qt's generic data structures included a function called QList::inSort(). Haavard Nord wrote that and didn't really document it, and when I wanted to write about it he only said it was useful sometimes. What was I to write? Use inSort() rather than insert() when that's useful
?
There is a chance that I simply deleted it when I couldn't write sensible documentation.
Two decades later I finally understand why inSort() was a good idea after all. It's useful for a particular kind general data structure that only occurs in GUIs: The list that should be mostly sorted, but should not be resorted once it's shown on-screen.
Consider a list of things that the user can select and either open or delete. Sorting by modification time can make sense (for some kinds of things), but if a UI-thing were to move when someone else updates the actual-thing, then it might move an instant before the user selects and deletes that. Oops.
Thus inSort(). Stupid name, but its presence would have been an improvement to some GUIs.
A few months I had a bug in a class without unit tests, and I can't stop thinking about the case.
There's a reason why I had no unit tests. I do use unit tests by default, but there are exceptions: If there is no real unit smaller than the program, I don't use unit tests. If the program only has to work once, I generally don't bother to test units. If correctness isn't formally knowable, ditto. And finally, if a unit test wouldn't really test.
Fuzzy correctness is the most common reason I skip unit tests. Earlier this year I skipped one because the goal of the change was to get rid of some unpleasant flicker. I managed to make the flickering cases uncommon, but I still don't know what unpleasant
really means, so how would I write a unit test? I've heard games have this problem quite often, because correctness can mean is fun to play
. But if flicker becomes bothersome again later, I know I will wish there were a unit test.
Tests that don't test are also a serious problem. In this case, the function that broke looked like return "foo" + bar(42, false)
, and the bug was that I used the wrong string constant. I very much suspect that the test would have been another one-line function with the same wrong string. Code review ought to pick such things up. Most code reviewers I've known wouldn't, though.
Most of the functionality in the class I was writing is outsourced to a backend. The class itself writes simple requests and processes equally simple responses. The caller calls millions of lines of code, but what broke was the simple, straight-line function that creates the request. And it broke spectacularly — the result was valid, it just changed the meaning of the request, made the wrong thing happen in the backend, which in turn instructed the frontend to change its state and usually issue some followup requests, the backend processed those too, and eventually the screen would show a valid but usually puzzling or misleading state.
I think that in such cases, I want protocol review, to answer a question such as is this a good frontend↔backend conversation given this user input?
or perhaps based on this frontend↔backend chatter, what do you think the user did?
.
It's a bit of a pity that the waterfall model of software development is out of fashion, not? But maybe it's possible to tweak scrum/agile development to be almost like waterfall? What would be necessary?
First, introduce cycles and milestones to more or less replace the continuous delivery. Adult supervision requires setting goals. It's okay to run CI tools, as long as you have at least a couple of future magic dates, call them next step along the waterfall
and final arrival at the ocean
or call them internal/partner alpha launch
and public launch date
.
Do it right instead of the continous improvement. The waterfall model says that it's cheaper to fix bugs earlier, so do it right once and it'll stay right. This too is simple to integrate into Scrum, just boost the code review and pre-implementation consultation. Talk about how important it is to have the right design and to avoid technical debt. Make technical debt seem worse than the many other kinds of software deficiencies. […More…]
The author of the most pleasant java code I've ever seen wrote the following paragraph on an internal mailing list last year, or perhaps the year before:
By the time I met my last significant mentor I had been programming for 15-16 years. I was skeptical to much of what he wanted me to do, but I shut up and gave it a few weeks — eventually incorporating much of his thinking into how I work and evolving my own style. He was amazingly bad at explaining things verbally, and to be honest: his code looks like shit. But he kept coming into my office and demanding all the right things of me; that I think about what I output (seriously, do you need that log output!?
), that I have near 100% test coverage even if it means the test code is 5 times larger than the code it tests, that I always remove code that isn't used, that I never implement methods that I don't need right now, that all public methods and classes are always documented and that the documentation be kept in sync with the implementation, that the code will build and run its tests on any machine and without screwing over other developers by assuming what is and isn't installed on the machine, that it compiles without warnings, that software is trivial to fire up, that any and all performance critical code is benchmarked, that code is never prematurely optimized but that design-work always consider performance implications of choices etc etc. I got yelled at every day for at least 3 months.
That mailing list was internal to a company that cared deeply about doing all the right things, avoided almost all of the cliché mistakes and yet missed deadlines serially. (I didn't know it yet, but later, the company would cancel its main product, weeks before release.) The demanding mentor was someone whose code looked like shit, yet demanded all the right things. There were parallels there, I thought, maybe I could use one to learn about the other. So I put it aside for a think and a ramble. […More…]
There is only one way to send email with SMTP: Connect, send EHLO, MAIL FROM, RCPT TO, BODY and the message. There are variations, but they're small. Most protocols offer implementers much more choice, many even demand much more.
This post is about a way to quantify the efficiency of the choices an implementer makes. It's a bit extremist, because extremism is simple and requires little thought: Bytes transmitted are defined to be useful if they're displayed on the user's display before the use case ends, and to be waste in all other cases.
The wasted bytes may be avoidable waste, unavoidable waste, Schrödinger's waste or even useful waste — it doesn't matter. This method applies a simple and unfair definition. Because the test is simple you can apply it quickly, and usually you learn something from doing the analysis.
The method leads to three numbers and hopefully nonzero insight: Percentage of bytes used to display, number of bytes downloaded per character displayed, and finally number of bytes used per character displayed. You get the insight not from the three numbers, but rather as a side effect of computing the three numbers.
I'll elaborate with two longish examples. […More…]
Today's subject: Translating a user interface to a language I don't know. I would have to assure myself of the quality of the translation. And I have heard many sad stories of miscommunication involving that particular language. What to do.
In the concrete case that started this train of thought, the application is one that displays and acts on user data. Like most applications. When something goes wrong it has to tell what or why. Also common.
This means that when all is right, 99% of the screen is used for user-provided data, and only the last per cent comes from the code. When something goes wrong, or a digression is required (File→Preferences is a digression), the screen contains mostly text/images/forms from the code.
In other words: An application that recovers from errors automatically instead of presenting them to the user offers less work for the translator. An application that needs little configuration is similarly easier to translate.
This is not a happy accident. There is a deeper truth behind it. All three varieties of better
are effects of the same cause: The application offers the user a better view, a wider and more transparent window, onto the user data.
This is the shortest program I have ever written and expected to do something:
118
243
I wrote that on a timesharing host in the eighties. The host had a Z80 processor and ran MP/M (a multiuser variant of CP/M), and I was curious to see whether my code would affect other users. The host did not have an assembler, but I knew the bit patterns for most assembly instructions by heart anyway.
I did one thing right: I didn't tell anyone in advance. Never ask a question if you already know what the answer will be. Instead I waited until just before the end of the class.
And I did two things wrong. What I wanted was
di ; disable interrupts
halt ; stop processing until interrupted
Sadly, halt is 118 and di is 243, which was my first mistake. And the second was that when it didn't work, I told someone (so what were you doing there at the end, Arnt?
), which led to a ban on such experiments before I had found the first mistake.
Why was Modula 3 so good?
The question has bothered me enough that I bought a new copy of Systems Programming with Modula 3 to reread. I reread, and was no wiser.
I liked the brevity of the language description. The designers explictly tried to make the language simple enough to describe in fifty pages. That may have something to do with the clarity of Modula 3 code.
I liked many of the minor features. I've mentioned the 31-bit integers before. Branded native types are another.
In Modula 3, you could define a variable as (I forget the exact syntax) branded msec cardinal timeout;
and get protection against unit confusion. If you branded a string as untrustworthy user-supplied input, you couldn't just assign it to an untagged string. If you branded an integer as msec
, you couldn't just pass it to a function which accepted a seconds
-tagged integer. That half-type gave a pleasant amount of protection against careless mistakes.
I seem to be saying that I liked Modula 3 because it was a compiled object-oriented language with simple syntax, sufficiently expressive, with some good features and no bad ones. Put that way, I admit that's my kind of language.
A year ago I talked at some length and frequency about the evils of Microsoft's reference application for the Xbox. One of the points I mentioned most often is that the thing links in four different JSON libraries, all deficient in some serious manner.
Today I added a third JSON library to an application, despite knowing that it already used two different ones.
Be conservative in what you send and liberal in what you accept
does not mean what you probably think it does.
Jon Postel was talking about how to interpret RFCs. He was, after all, the RFC editor. When an RFC says that a particular protocol uses text lines with a maximum length of 512 bytes and CRLF as line terminators, you might be forgiven for wondering whether that's 510+2 or 512+2 bytes. In most cases there is some sentence that makes it clear, but that sentence can be easy to overlook.
If you overlook it, or you see it but think other implementers may overlook it, then Postel's Principle applies. In the example above being liberal
means accepting 512 bytes plus CRLF, and being conservative
means sending 512 including CRLF.
Postel's principle does not mean that you should accept 1024-byte lines or any other thing which the RFC forbids. Jon Postel was the RFC editor, he didn't want you to ignore the RFC's stated line length. His principle is about how to handle the boundary case whenever the boundary is underspecified or misunderstandable.
The commits I ranted about yesterday aren't very large compared to what I wrote. More than 90% of the code I wrote disappeared while I merged commits for review.
The biggest block of code that disappeared was a false start. I had an idea for how to solve a problem, wrote much code, and eventually saw that the program had become lopsided. The percentage of code dedicated to that one problem was far too large. Once I understood that I quickly found a much better approach. Smaller. More robust.
That detour will not be visible in the version history my colleagues can see. That history shows a different Arnt, one that went more or less straight to the right design. […More…]
The Roku is not a general computer. It has no keyboard and no persistent storage.
There is an on-screen keyboard, but none of the examples use it, and so far I haven't seen an app use it either. The spirit of the Roku is that apps give users a screenful of things to choose from, and users choose. Equally, it has support for USB, but read-only so apps can see what's on a USB stick, but never, ever store anything. Very secure: A user can stream, but cannot store and therefore cannot copy. DRM taken to its logical conclusion.
Apps start from scratch every time. Stop and restart and app, and the app has lost all state. The only way to cache state is to use the device registry, which is limited to 16k and vaguely discouraged.
I like it, it has a certain honesty and simplicity.
There seems to be no way to cache web resources, so an app had better be able to start up without needing any web resources, or else it will start up very slowly.
The same applies later: If a web resource is slow, the UI blocks. I managed to avoid strict blocking using asyncGetToString() and asyncPostFromString(), but the result is still not quite good. Even though he UI reacts at once, the reaction is usually to present the outline of a screen at once and only fill it in a little later.
The key to achieving even this was to use the same roMessagePort for all screens and all roUrlTransfers, and write a function to process all roUrlEvents and perform callbacks to update whatever needs to be visited. I had to write three lines of boilerplate near every call to wait(), but the rest was quite pleasant. I got some HTTP caching for free too, so selecting the same item a second time works instantly.
There's a brightscript emacs mode floating around the web; I hacked a bit on it and someday maybe I'll post my version to github.
Mark Roddy, who I now see may be the original author of brightscript-mode.el, has written a test framework.
I cannot count the number of times I've expected a=b;
to work. My fingers type semicolons on their own.
The daily standup and periodic sprint planning in Scrum expose ideas to more people. There's more chat about things. Methodic code review pushes in the same direction.
That has many good effects. One which may not be so good is that dubious features are easily killed before they're implemented, or rejected when the first part is reviewed. Sometimes that makes me unhappy.
Dubious features are Schrödinger's cats: They can be anything from damaging to insanely great.
Insanely great features are insanely great in hindsight, but the ones I've written weren't great in advance, and I fear most of them wouldn't have passed the Scrum process. It's so easy to say no and concentrate on the sprint story. An answer like write it and see, we can always ditch it afterwards
isn't in the spirit of scrum.
I suppose that's no bad thing, overall. More deadlines met. But fewer inspired features.
FAQs happen, and have to be handled. There are four ways. A sorted commented list (I promise this won't be a rant):
Do nothing. A valued approach, and there is much to say in its favour. For an opensource hacker who's basically writing code to scratch his own itch (using the male pronoun seems safe in this context) there's no intrinsic reason to care about FAQs at all. […More…]
{kind=link}